
Non è una novità che spesso i dati aziendali siano ospitati da diversi datastore e differenti motori relazionali. Oltre a SQL Server spesso abbiamo dati in Oracle, in MongoDB, o addirittura su files CSV prodotti direttamente dagli utenti.
In passato le alternative per avere accesso ed eseguire query su tutti questi dati insieme erano sostanzialmente due (e mi perdonerete alcune semplificazioni ma ci stiamo focalizzando sul mondo SQL Server):
1. utilizzare un processo ETL per portare i dati di interesse dalla loro sorgente ad una destinazione consolidata, oppure
2. per le fonti dati supportate, usare un Linked Server su un’istanza master per connettersi direttamente alle sorgenti dei dati ed eseguire query su di esse come se fossero in locale.
Se il requisito era di eseguire query direttamente ed ottenere risultati in tempo reale, la soluzione 2 era un obbligo, ma poneva davanti ad una serie di ulteriori problemi. In estrema sintesi, un Linked Server è un’istanza di un OLE DB Provider configurata per puntare ad una specifica OLE DB Data Source. Se la data source è SQL Server, nessun problema, il provider ce lo portiamo dietro dall’installazione del database engine. Ma se la data source è, ad esempio, Oracle, il provider va installato ad hoc, e richiede la presenza, sul sistema, del Oracle Client della giusta versione con il relativo TNSNAME.ORA. Insomma, non proprio qualcosa di banale da gestire.
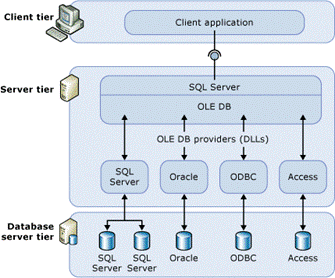
A partire dalla versione 2016 di SQL Server però, fa la sua prima apparizione PolyBase, e questo scenario subisce un upgrade importantissimo, perchè PolyBase rappresenta un layer software che sostituisce OLE DB e permette di eseguire query T-SQL direttamente sulla fonte dati e senza la necessità di installare software per le connessioni client.
E già con questo torniamo a casa vincitori! Ma vediamo meglio a che punto è arrivata la Data Virtualization tramite PolyBase in SQL Server 2022.
Dettagli tecnici
PolyBase è una serie di servizi che fanno parte del setup di SQL Server (SQL Server PolyBase Engine Service e SQL Server PolyBase Data Movement Service), e che possiamo installare insieme al database engine o in un secondo momento.
PolyBase può essere configurato in due modalità:
- Use the SQL Server instance as a standalone PolyBase-enabled instance
- Use the SQL Server instance as part of a PolyBase scale-out group
Uno scale-out group è una modalità di aggregazione di servizi PolyBase su diverse istanze per eseguire query in parallelo su quantità di dati molto grosse, come blob in Azure o oggetti Hadoop. In un gruppo, una istanza è detta head node ed è quella che riceve la query e la distribuisce ai compute nodes, che poi la eseguono in maniera distribuita.
Un’istanza standalone è un’istanza in cui head node e compute node coincidono, e che non può essere scalata.
L’installazione di PolyBase crea delle regole di firewall che devono essere attivate perché la caratteristica possa funzionare:
- SQL Server PolyBase - Database Engine - <SQLServerInstanceName> (TCP-In)
- SQL Server PolyBase - PolyBase Services - <SQLServerInstanceName> (TCP-In)
- SQL Server PolyBase - SQL Browser - (UDP-In)
Quindi, attenzione ai vostri firewall perimetrali!
Una volta installati i servizi, devo attivare la caratteristica sulla mia istanza:
exec sp_configure @configname = 'polybase enabled', @configvalue = 1;
RECONFIGURE;
Una volta attivata la caratteristica, non devo fare altro che creare oggetti SQL che rappresentano gli endpoint delle mie fonti dati, ed il gioco è fatto: SQL server automaticamente userà nativamente le API per accedere a storage di tipo Data Lake Storage, Blob Storage o S3, oppure si appoggerà ai servizi PolyBase per le altre richieste (i servizi sono comunque da installare in ogni caso, quindi attenzione alle scorciatoie troppo facili!).
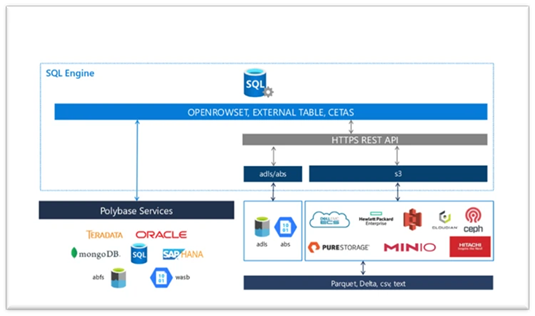
Come si usa
Una volta installati e configurati i servizi PolyBase, per accedere ai dati esterni cosa devo fare?
Impostare delle credenziali
Non credo esista alcuna implementazione RDBMS priva di autenticazione, quindi la prima cosa che devo fare è creare delle credenziali da usare nelle mie connessioni.
Le credenziali sono oggetti generici di SQL (DATABASE SCOPED CREDENTIAL), che vengono immagazzinati nel database di contesto, e che vengono protetti tramite la Database Master Key (che quindi deve essere configurata). A seconda del tipo di datastore supportato, le mie credenziali dovranno essere in un formato specifico.
Ad esempio, se dal database Analytics debbo accedere ad un file CSV in uno storage compatibile S3 tramite Basic Authentication, la credenziale dovrà essere di questo tipo:
USE [Analytics];
GO
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'S3 Access Key',
SECRET = '<AccessKeyID>:<SecretKeyID>'
Scegliere il formato
In alcuni casi, come ad esempio se devo accedere a files contenuti in Azure o in storage compatibile con S3, dovrò anche indicare questi files come sono fatti. In SQL Server 2022 possiamo definire formati file basati su CSV, Parquet, Hive RCFile e Hive ORC.
Ci sono anche formati specifici di alcuni datastore: JSON per SQL Edge e Delta per Synapse Serverless SQL Pool.
Così, se dovrò accedere al contenuto di un file Parquet, dovrò definire un formato come il seguente:
CREATE EXTERNAL FILE FORMAT file_format_name
WITH (
FORMAT_TYPE = PARQUET
, DATA_COMPRESSION = 'org.apache.hadoop.io.compress.GzipCodec'
);
Scegliere in che modo accedere ai dati
Una volta impostate le credenziali, ho tre modi per accedere ai dati del mio datastore esterno.
- OPENROWSET: questo metodo permette di eseguire analisi esplorative di files in Azure o in storage compatibile S3, creando una sorta di vista sul contenuto, senza la necessità di usare costrutti duraturi. L’openrowset viene costruito ogni qualvolta viene richiamato, ed è quindi poco adatto ad utilizzi continuativi.
- CREATE EXTERNAL TABLE (CET): questo metodo permette di creare, a partire da una Data Source, un oggetto stabile all’interno dell’istanza, che referenzia i dati specifici a cui debbo accedere. Ad esempio, se debbo accedere a dati contenuti in un file CSV all’interno di un Azure Blob Storage, dovrò eseguire qualcosa come:
CREATE EXTERNAL DATA SOURCE data_source_name with (
LOCATION ='wasbs://<blob_container_name>@<azure_storage_account_name>.blob.core.windows.net',
CREDENTIAL = credential_name
);
CREATE EXTERNAL FILE FORMAT file_format_name WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR =';',
USE_TYPE_DEFAULT = TRUE))
CREATE EXTERNAL TABLE [dbo].[table_name] (
[Column_1] int NOT NULL,
[Column_2] int NOT NULL,
[Column_3] int NULL,
[Column_4] float NOT NULL,
[Column_5] int NOT NULL
)
WITH (LOCATION='<path>',
DATA_SOURCE = data_source_name,
FILE_FORMAT = file_format_name
);
L’external table è un costrutto che contiene localmente tutti i metadati dell’oggetto esterno, ma non l’oggetto stesso, quindi attenzione ai backup!
- CREATE EXTERNAL TABLE as SELECT (CETAS): questa potente modalità permette di creare una tabella esterna, come sopra, ma in questo caso possiamo popolarla esportandovi i record ottenuti attraverso una query T-SQL. Per poter usare questa modalità occorre attivare la caratteristica allow_polybase_export:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'allow polybase export', 1;
GO
RECONFIGURE;
GO
Una volta attivata, possiamo ad esempio esportare in un file parquet il contenuto di una tabella (di seguito un esempio basato su storage compatibile S3):
CREATE EXTERNAL TABLE ext_sales
WITH (
LOCATION = '/<path>/<file>.parquet',
DATA_SOURCE = s3_eds,
FILE_FORMAT = ParquetFileFormat -- Defined elsewhere
) AS
SELECT *
FROM <table_name>;
GO
Delegare il calcolo (pushdown computation)
Come suggerito dal nome, SQL Server 2022 è in grado di delegare attività di join, proiezione e filtro al datastore dove si trovano i dati, per ottimizzare le performance delle query lato istanza di esecuzione. Come facile intuire, questa opzione va valutata con attenzione caso per caso, perché se è vero che andiamo ad alleggerire il carico locale dell’istanza, ed il volume delle informazioni trasmesse via rete, è altrettanto vero che stiamo andando a caricare il datastore di destinazione, e questo può non essere ottimale, soprattutto nei casi in cui il datastore è un’istanza di database con risorse limitate.
Di default l’innesco della pushdown è automatico in presenza di specifici predicati, ma è possibile forzarlo o disattivarlo sia in creazione della EXTERNAL DATA SOURCE, che tramite OPTION all’interno della SELECT:
OPTION (FORCE EXTERNALPUSHDOWN)
oppure
OPTION (DISABLE EXTERNALPUSHDOWN)
Questo ORACLE dove lo metto?
Fino ad ora abbiamo parlato genericamente di Data Virtualization. Come si collega quanto scritto finora con l’integrazione verso un’istanza ORACLE?
Anzitutto, la configurazione della external data source. Di base posso connettermi direttamente, specificando la location nella data source:
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (LOCATION = 'oracle://<server address>[:<port>]',
CREDENTIAL = credential_name)
Se ho a disposizione un TNSNAMES.ORA tramite cui mantengo i puntamenti alle mie istanze, posso usarlo direttamente nella data source:
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (LOCATION = 'oracle://<TnsServerName>',
CREDENTIAL = credential_name,
CONNECTION_OPTIONS = 'TNSNamesFile=<file_path>\tnsnames.ora;ServerName=<TnsServerName>'
)
Poi l’autenticazione, che dovrà essere di tipo basic; questo perché il connettore al momento non supporta Kerberos.
Oltre ad autenticarmi direttamente, potrò anche usare la proxy authentication per limitare le grant dell’utente che usa la data source:
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (LOCATION = 'oracle://<server address>[:<port>]',
CONNECTION_OPTIONS = 'ImpersonateUser=%CURRENT_USER',
CREDENTIAL = credential_name
);
Creati gli oggetti fondamentali, potrò ora creare external tables o openrowsets, a seconda delle esigenze, per poter eseguire query sulla mia istanza remota. Nella creazione delle external tables, occorre fare attenzione ai seguenti aspetti:
- Attenzione al case (maiuscolo/minuscolo) del nome qualificato delle tabelle Oracle. In estrema sintesi, per ORACLE i nomi employee ed Employee sono diversi.
- Attenzione alla Collation. Nel caso la collation dell’istanza SQL Server differisca da quella dell’istanza ORACLE, dovrò esplicitare specificamente quella di ORACLE nella creazione della External Table in SQL.
- Attenzione alle credenziali. ORACLE ha una gestione delle credenziali che è evoluta nel tempo, e potreste imbattervi in un comportamento inconsistente durante il processo di autenticazione. In questa sede non è possibile approfondire oltre un certo limite, ma in estrema sintesi le password, a partire dalla versione 11g, sono diventate case sensitive e parallelamente sono state introdotte opzioni nel file TNSNAMES.ORA e nelle system variables per controllare questa caratteristica. Il risultato può essere che in alcuni casi una password effettivamente corretta non funzioni; in quel caso occorre entrare nello specifico della situazione per trovare la giusta soluzione.
Infine, anche se non necessario, in caso di external tables è buona norma creare le statistiche per ottimizzare le performance. Ricordate che, anche se una external table non contiene effettivamente i dati originali, ne contiene i metadati che vengono usati per i calcoli in caso non sia possibile fare il pushdown, e quindi avere le statistiche locali può essere estremamente utile.
Conclusioni
Alla fine, quali vantaggi può darci PolyBase per interagire con le mie istanze ORACLE? Ecco alcuni esempi.
- Semplicità di implementazione. Al di là di dover disporre di un’istanza SQL Server 2022 (cosa che probabilmente molte aziende comunque hanno già a disposizione), non è necessario dover gestire alcun altro requisito software come l’OCI Client, o mantenere un TNSNAMES.ORA in giro per i propri server.
- Semplificazione dei processi ETL. Se il mio sistema di BI è già basato su cloud, oppure è in procinto di essere portato in cloud, la capacità CETAS di PolyBase ci permette di togliere dalla catena un sistema ETL che mi porta in cloud i dati di ORACLE. Creando le external tables necessarie posso esportare le mie elaborazioni ed aggregazioni direttamente in un file parquet o csv in cloud, sostituendo soluzioni generaliste come SSIS, Azure Data Factory o AWS Glue.
- Semplificazione della reportistica in tempo reale interna. La lettura diretta dei dati dalla sorgente, insieme alla semplicità di implementazione, lo rendono uno strumento ideale per integrare nella mia reportistica informazioni in tempo reale, sia che venga erogata tramite SSRS che tramite Power BI con Data Gateway.
- Miglioramento del modello autorizzativo. Le External Tables sono oggetti che possono appartenere ad uno schema, e quindi posso esercitare un modello autorizzativo dettagliato, esattamente come posso fare sule tabelle e sulle viste. Inoltre, su di esse posso definire delle policy per la Row Level Security che mi danno ulteriore controllo su cosa esporre ai fruitori di quei dati.
